
简单的 OS 性能分析速查(运维场景)
预备知识库:计算机组成原理(如内存 Hierarchy、CPU 基本组成),操作系统原理(kernel/user space、资源抽象、进程状态抽象等)。
以下是很零碎、经验化的思路,总结下来方便回顾。
1. CPU 分析
业界主流的对于 CPU 忙碌情况的指标是 “Load Average”,定义为 处于可运行状态(running)和不可中断睡眠(uninterruptible sleep,通常在等待 I/O)的进程数平均值。相关知识参见 附录 II。
Linux 上使用 top 类指令查看到的 load average 通常有 3 个数字,分别代表在过去 1 分钟、5 分钟、15 分钟内的 load average。
例:load average: 2.35, 1.87, 1.25 表示 1 分钟平均有 2.35 个进程在等待 CPU 或 I/O 资源(粗略认为)。
一般情况正常工作的理想状况 load average 约等于 CPU 核心数。load average 两倍于 CPU 核心数超过 5 分钟认为过载预警,4 倍于 CPU 核心数认为严重过载。
另一个指标是 CPU 利用率(CPU 时间分配比例)。也可通过 top 类指令观察到:
%usr(us):用户进程占用 CPU 时间百分比(应用程序)%nice(ni):手动调整过优先级的用户进程占 CPU 时间百分比%sys(sy):内核进程占用 CPU 时间百分比(系统调用、中断处理)%idle(id):CPU 空闲时间百分比%iowait(wa):CPU 等待 I/O 完成的时间百分比(不是 CPU 被占用,而是空闲但有未完成的 I/O 请求)%softit / %hardit(si / hi):处理软中断/硬中断的 CPU 时间占比%steal(st):虚拟机等待物理 CPU 的时间百分比(仅虚拟化环境)
此外 vmstat 指令能提供更多全局数据,如:
1 | vmstat 1 |
- r (running):等待 CPU 的进程数,持续 >> CPU 核心数表示 CPU 瓶颈
- b (blocked):等待 I/O 的进程数,持续 > 0 可能存在 I/O 瓶颈
- us + sy:持续 > 90% 表示 CPU 资源紧张
- cs (context switch):context switch 次数,> 10 万/秒 可能存在资源竞争问题
排除 CPU 瓶颈的手段:
确认 CPU 大致状况:
1
2
3top -H # -H 线程级别统计
htop
vmstat 1 # interval 1s, procs/memory/swap/io/cpu 统计确认哪个进程、哪些 CPU:
1
2mpstat -P ALL 1 # 按 CPU 核心统计
pidstat -u 1 # -u 按进程 CPU 使用追踪进程内的瓶颈,需使用
perf生成 flame graph;想知道某些进程的 CPU 亲和性,或者处于性能测试的原因想将进程绑定到特定 CPU 上,可以使用
taskset -c 0-3 ./app这样的方法;想手动调整特定进程的优先级,可以使用这样的指令来告诉调度器:
nice -n -20 ./critical_app(nice 值越小意味着越倾向于让出 CPU 资源,因此优先级越高,范围 -20 到 19,默认 0);
2. 内存分析
内存是否到达“极限”的核心指标:可用内存(available)和 swap 使用率。
一般可以通过 free 指令查看全局的粗略信息:
1 | free -h |
注:shared 表示 tmpfs 等共享内存使用量
[!IMPORTANT]
注意可用内存:
avail = free + buff/cache - reclaimable。因此在判断内存瓶颈时,不能只看
free命令的 free 列,因为 Linux 会充分利用空闲内存作为缓存。
除了 free,vmstat 也能查看内存相关稍详细一点的全局信息:
1 | vmstat 1 |
- swpd:已使用的交换分区大小(KB)
- si(swap in):每秒从交换分区读入内存的数据量(KB/s)
- so(swap out):每秒从内存写入交换分区的数据量(KB/s)
- in(interrupt):每秒发生的中断总数(page fault 中断包含其中)
- 关键阈值:si + so > 10MB/s 持续 5 秒以上,表示存在严重的 thrashing,working set 大于现有内存资源。
如果想了解更详细关于 page fault 的情况来掌握内存使用情况,不止需要了解 swap,还需要了解 page fault 频率等等。
通过 sar 指令查看 page 的交换和缺页异常的情况:
1 | sar -W 1 |
- pswpin/s, pswpout/s:每秒交换入/出的页数
- fault/s:每秒 Page Fault 总数
- majflt/s:每秒 Major Page Fault 数量
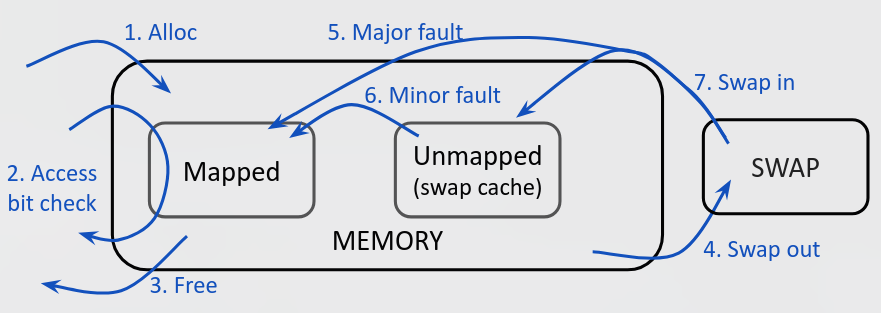
排除内存瓶颈的手段:
使用
top/free/vmstat/sar类型的指令查看全局的内存主存、swap 使用情况,包括占用/增速;定位哪个进程正在造成这个问题:
1
2
3
4按 RSS(Resident Set Size) 排序
ps -eo pid,user,rss,cmd --sort=-rss | head -10
-r 显示内存统计信息
pidstat -r 1针对这个进程了解内存使用情况:
1
2
3
4监控特定进程的内存增长
watch -n 1 "ps -p <pid> -o rss,vsz,cmd"
查看进程的详细内存映射
cat /proc/<pid>/smaps | less更细粒度(进程甚至线程内部)的判断则需应用相关的调优手段。例如对 Java 应用可以通过 JVM 提供的 perf 工具(如
jstat/jstack/jmap等)。
[!NOTE]
值得关注的是,在粒度细化到针对特定进程时,我们还有一些指标来衡量内存使用情况(下面表格为 LLM 生成内容):
内存指标 定义 是否包含共享内存 是否包含 Swap 使用场景 RSS (Resident Set Size) 驻留在物理内存中的进程内存大小 ✅ 完整计入 ❌ 仅物理内存 快速查看进程内存占用 VSZ (Virtual Memory Size) 进程虚拟地址空间总大小 ✅ 完整计入 ✅ 包含 了解进程地址空间需求 PSS (Proportional Set Size) RSS + 按比例分摊的共享内存 ✅ 按进程数均摊 ❌ 仅物理内存 精确计算进程真实内存开销 USS (Unique Set Size) 进程独占的物理内存大小 ❌ 仅独占部分 ❌ 仅物理内存 分析内存泄漏、优化独占内存
3. 磁盘 I/O
硬盘是否到达“极限”的指标:IOPS 和 吞吐量;
- IOPS 极限:每秒能处理的请求数(一般小文件随机读写瓶颈);
- Throughput 极限:每秒能传输的数据量(一般大文件顺序读写瓶颈);
[!IMPORTANT]
在判断一个硬盘到达极限时应该遵循指标分析,方便后续优化工作。
另外 IOPS 还受制于 CPU 性能、Throughput 还受制于内存性能(看具体场景)。
这套指标不仅适用于存储 I/O,还适用于网络 I/O。
使用 iostat -x [interval] 观察硬盘的指标(-x 打印 extended 信息,-z 不打印为 0 的数据):
1 | Device r/s w/s rkB/s wkB/s %util |
r/s(读 IOPS)、w/s(写 IOPS)之和是 IOPS 数据;
rkB/s(读吞吐量)、wkB/s(写吞吐量)之和是 Throughput 数据;
iostat的%util指标无法直接判断硬盘 I/O 极限。因为%util的定义是 “磁盘忙碌时间占比”。例:该磁盘 1 秒内 0.98 秒在处理请求,则当前
%util值为 98%;对机械硬盘(HDD):每次只能处理一个请求(磁头只有一个),
%util为 100% 意味着满负荷(即到达 I/O 极限);对现代 SSD / NVMe:多 channels 设计,可并行处理上百请求,
%util为 100% 代表每时每刻都不是完全空闲的;一个 NVMe 盘能同时处理 128 个请求,现在有 10 个请求一直在队列中处理,
%util为 100%,但是 90% I/O 能力 not fully utilized;
iostat的await指标能间接判断硬盘的 I/O 极限。因为await的定义是请求从发出到完成的平均时间(即平均周转时间 ATT),单位毫秒;await异常升高(相对于同型号正常值)证明当前 workload 接近 I/O 极限。注意不同磁盘的 baseline(正常值基准)不一样。可以使用
fio工具测试磁盘的 IOPS / 吞吐量极限:1
2
3
4
5
6
7测随机读 IOPS
fio --name=randread --ioengine=libaio --direct=1 --bs=4k \
--iodepth=64 --rw=randread --size=1G --runtime=30
测顺序写吞吐量
fio --name=seqwrite --ioengine=libaio --direct=1 --bs=1m \
--iodepth=32 --rw=write --size=1G --runtime=30
排除硬盘压力/瓶颈的手段:
确认是否是 I/O 问题:
top选项的wa%(iowait percentage)指标:15%-20% 记为高占用。定位硬盘的具体问题,哪块设备、什么瓶颈:
1
iostat -x 1
哪个进程正在造成这个问题:
1
2
3
4通过检查 kernel 提供的 /proc 中的 I/O 统计信息
sudo iotop -oP # -o 仅正在执行 I/O 操作的进程;-P 仅进程(不包括默认显示的线程)
sysstat 工具包一部分
pidstat -d 1 # -d I/O 统计信息,interval 1s 采样间隔这个进程正在读写什么文件:
1
2lsof -p <pid>
strace -p <pid> -e trace=read,write,open -f
Appendix I. 场景实战
Scene A. 不可中断睡眠
关于是否可中断睡眠的辨析:
- 块设备操作,如磁盘读写操作涉及复杂的硬件交互,必须保证操作的完整性,所以进程操作时一定位于不可中断睡眠状态;
- 错误。D/S 区分与“是不是磁盘 I/O” 无关。有些 I/O 操作需要 D 状态是因为 Kernel 打断后没法恢复状态/ roll back,与硬件性质也无关。
- 观察到与 NFS 相关的大量进程长期进入 D 状态 是没关系的,因为 NFS 锁需要不可中断睡眠来保证操作完整性。
- 半对,应该检查具体原因。NFS 历史上会导致很多 D 状态是设计缺陷,现在的 kernel 可以尽量避免出现 D 状态;
- 使用不可中断睡眠的其中一个原因就是,kernel 在执行 nested signal handlers 时会出问题。
- 错误。不可中断睡眠与内核处理嵌套信号句柄无关。本质上就是 Signals 默认会强制退出进程睡眠状态,如果 kernel 不能在此时 abort 操作(回到用户态为时尚早),那么使用 S 就是不安全的,这个进程需要 D 状态。
Scene B. CPU 瓶颈
下面的情况:
1 | uptime |
注意到:
- 这是一个 8 核机器,一分钟内 load average 说明存在 CPU 资源压力;
%usr = 85.21%表明是用户进程导致的 CPU 压力;- 接下来需要使用
pidstat -u 1或其他指令查看具体进程使用情况;
Scene C. I/O 等待会影响 Load Average
下面的场景:
1 | vmstat 1 |
看起来 id=0% 是 CPU 资源受限吗?并非,wa=85% 说明 CPU 有 85% 时间在等待 I/O 完成,很可能是 I/O 瓶颈。
注意 bi=2345、bo=6789:块设备每秒读写次数高,需要结合 iostat 进一步分析 I/O 瓶颈问题。
Scene D. 内存是否存在压力
1 | free -h |
available 仅 2.1Gi(总内存 62Gi 的 3.4%),远低于 10% 的健康阈值,存在内存问题。
wa=20% 说明 CPU 有 20% 时间在等待 I/O 完成,但另外的数据证明了并非用户态程序的 I/O:si=8192KB/s, so=12288KB/s,持续的高 swap I/O 活动证明可能存在大规模的 Thrashing 现象,说明系统存在严重物理内存短缺问题,需要立即定位进程并查找原因:
1 | pidstat -r 1 |
发现 PID 为 1234 的 Java 应用存在持续的 major page fault,应使用 JVM 相关工具对业务逻辑进行进一步排查。
Scene E. 磁盘 I/O 检查
1 | iostat -x 1 |
如上所示,可以发现:
nvme0n1设备并不存在接近极限的问题:await 约 0.1 ms,队列长度 1.84;sda设备达到极限:await 高达 45-62 ms,队列积压 16 个请求;
Scene F. 磁盘 I/O 瓶颈估算
某 NVMe 硬盘标称 50 万 IOPS、3 GB/s 吞吐。估计:
“数据库大量随机读写,4KB 小块” 时的场景:先达到 IOPS 极限(50w × 4KB = 2GB/s),此时吞吐量未达上限;
“视频转码,顺序读写超大视频文件” 时的场景:大概率先达到吞吐量上限(3 GB/s 时 IOPS 仅数千);
Appendix II. Review: About Process States
经典操作系统理论中的进程状态(Created/Ready/Running/Blocked/Terminated)是一个抽象模型,描述了进程生命周期的基本阶段。而 Linux 进程状态(如下)是具体工程实现,提供了更细致和实际的状态描述。
1 | S Interruptible sleep (waiting for an event to complete) |
二者映射关系如下:
Ready + Running -> R
- 理论中的 Ready(就绪)和 Running(运行)状态在 Linux 中合并为 R 状态,这是因为在 Linux 调度器实现中,这两个状态在内核数据结构层面难以严格区分;
- R 表示 “Running or runnable (on run queue)”,即要么正在 CPU 上执行,要么在 run queue 中等待 CPU;
Blocked -> S + D
理论中的 Blocked(阻塞)状态在 Linux 中细化为两种:
- S (Interruptible sleep): 可中断睡眠,等待事件完成,可以被信号唤醒;
- D (Uninterruptible sleep): 不可中断睡眠,通常是等待 I/O 操作完成,不能被 OS 的信号中断;
这种细分反映了实际系统中阻塞的不同性质和处理需求。
区分的根本意义辨析:D state is not primarily about protecting “critical kernel processes.”
It is about protecting specific *wait contexts* where interruption would cause:
- resource leaks;
- inconsistent kernel state;
- or impossible rollback;
A task enters D when it sleeps while holding resources that cannot be safely released or unwound if a signal arrives.
即:确保某些关键上下文不能被打断 (D),同时顺便保证系统性能 (S),与 I/O 或锁无关,只与 Kernel 有没有能力在 signal 打断后 context switch 原样恢复回去有关。举例场景:
I/O Subsystem 的特殊性:
虽然:Disk I/O is not inherently uninterruptible.
但是:Many I/O paths used to require D because they could not be safely rolled back, NOT because of “hardware complexity”.
Kernel Signal 的正确性(需要 D):防止在 kernel 关键路径上处理信号导致内核数据结构不一致、避免在持有重要锁时被中断导致死锁(持锁顺序问题)、确保资源清理工作能够完整执行等。这里需要 avoids partial execution states.
存在很多可以安全中断的等待(需要 S),如等待用户输入、等待定时器、等待非关键资源;
并不是所有持并发资源锁等待 / 等 IO 资源的进程都需要是 D 状态。甚至这么说:绝大多数持锁/或者等 IO 的进程(如
mutex_lock,rwsemaphore,futex waits,pipe reads,socker rw,poll/select/epoll, 绝大多数文件系统操作等)都不需要进入 D 状态。进入 D 状态的评判标准:The task must sleep (cannot spin).
If a signal arrived at that sleep point, the kernel could not safely abort the operation and unwind all held state.
Terminated -> Z + X
- Z (Zombie): 进程已终止但父进程尚未调用
wait()回收其资源; - X (Dead): 完全终止状态,通常不会在 ps 这样的命令中看到;
- 理论模型中的 Terminated 在 Linux 实现中被细化为资源回收的不同阶段;
- Z (Zombie): 进程已终止但父进程尚未调用
Linux 特有状态
- T (Stopped): “Stopped, either by a job control signal or because it is being traced”,这个状态在经典理论模型中没有直接对应,可以看作是 Blocked 的一种特殊情况,被 shell / 调试工具等控制的进程;
- W (Paging): 在 Linux 2.6.xx 内核后已不再有效;
 wechat
wechat- alipay













