
OS 的特权级切换与内存管理总览:以 Linux AArch64 为例
特权级切换与内存管理这两块知识一直是 OS 的极其极其重要的组成部分:特权级切换是 OS 上下文切换和调度的基石,而内存管理则是一切隔离性(进程抽象)、资源可用性的基石。可惜对于初学者而言太过庞大,并且它们通常相互涉及,以至于总是掌握不了全貌。
笔者想从尽可能全面的视角记录总结一下它们究竟在做什么,方便日后查阅笔记、快速理解,因此不会过于深入细节(例如不会介绍 Buddy System 和 SLUB 机制的具体内容)。
最后我们将总结并运用已经了解的知识,讨论一下全局视角下的 OS 内核栈。
如有错误,欢迎读者勘误斧正。
下面内容将以 AArch64 为例。
建议复习:通用寄存器
x0-x30、PC 程序计数器、4 个栈寄存器SP_ELx、3 个异常链接器ELR_ELx(从 1 开始)、3 个程序状态寄存器SPSR_ELx、2 个页表基地址寄存器TTBRx_EL1(注意只有 EL1 级别)、TCR/SCTLR/SCR/TPIDR/MPIDR 这些常见寄存器的用途。
A. 特权级切换
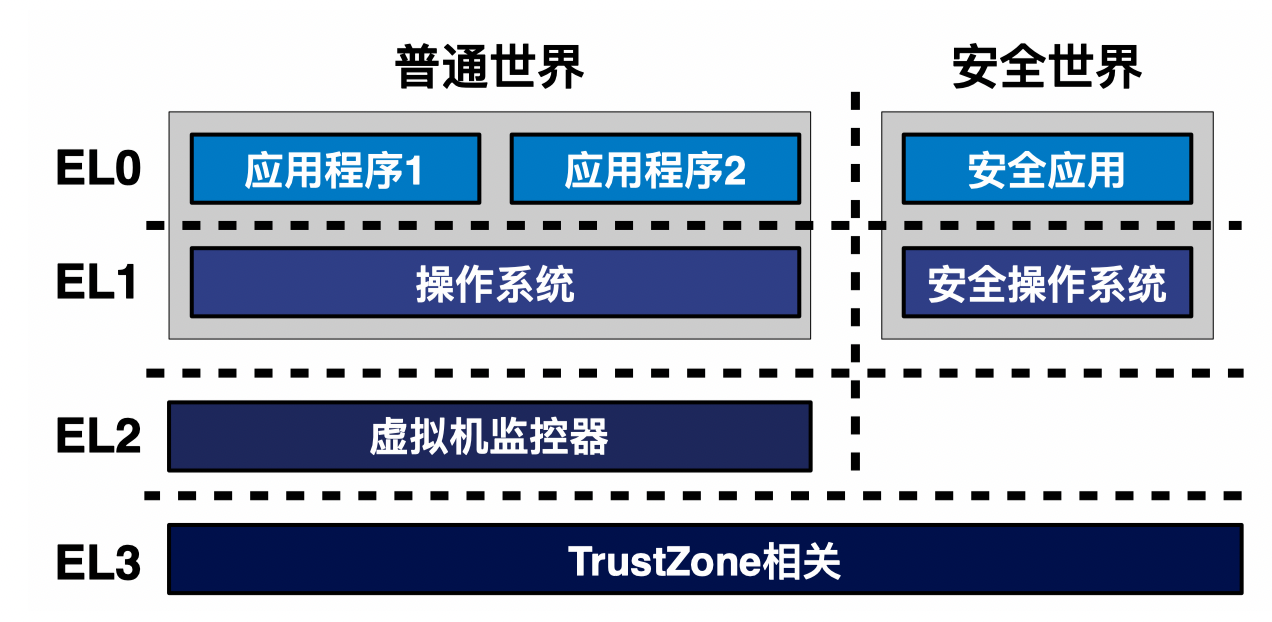
EL0:用户态程序、EL1:内核、EL2:hypervisor、EL3:monitor;
ARM 特权级切换和 x86 一样,都需要是 Context Switch,因此需要保存一些运行时数据(通用寄存器值、系统控制和特殊寄存器值、PCB/TCB、文件描述符、内存管理结构体等等)。
首先 ARM 本身的特权级比 x86 的复杂(Ring 0/3),因此切换过程对应地复杂一些。寄存器的保存方法如下:
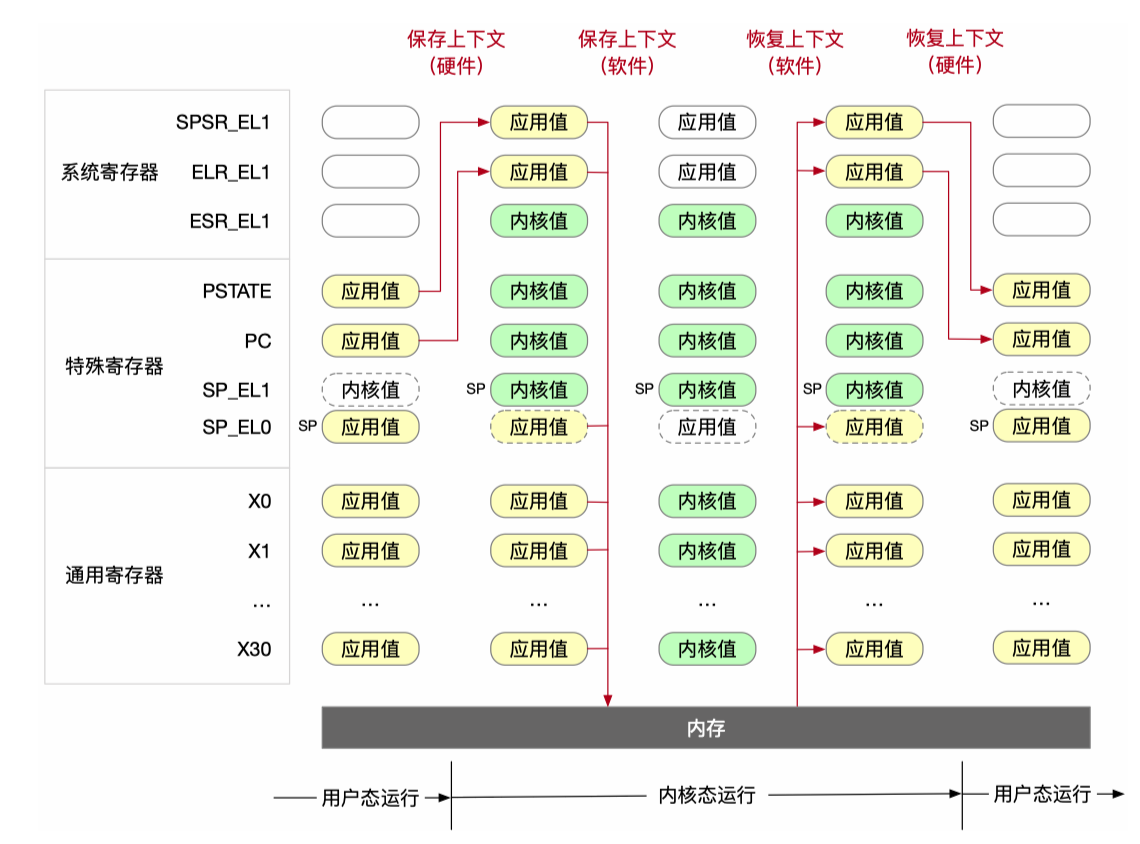
总结一下 ARM CPU 在特权级切换时硬件和软件所执行的任务:
首先无论特权级切换是硬中断还是软中断引起的,硬件都会开始处理上下文切换的工作:
当前使用的所有
EL0寄存器全部切换到使用EL1寄存器(例如SP_EL0->SP_EL1、TTBR_EL0->TTBR_EL1);备份特殊寄存器:特殊寄存器 PC 保存到
ELR_EL1方便返回当前用户态进程(和 x86 相同,如果是软中断则保存中断位置下一条指令的地址,如果是硬中断则保存中断位置当前指令地址)、特殊寄存器 PSTATE 保存到SPSR_EL1方便恢复当前用户态进程程序状态;写入系统寄存器
ESR_EL1:将异常事件的原因代号保存在ESR_EL1寄存器,例如是svc指令导致(对应 x86syscall,trap)还是缺页导致(fault)还是其他原因;如果是 page fault,那么将触发的内存地址保存在FAR_EL1寄存器(回忆 x86 的 CR2 寄存器)恢复特殊寄存器:通过
ESR_EL1寄存器和VBAR_EL1寄存器(Vector Based Address Register,回忆 2.1.7)计算出异常处理函数的起始地址,并写入 PC;SP_EL1保持原样就行;PSTATE按需求设置,例如会被硬件设置为目标异常级别(EL1)的默认状态,即 DAIF 掩码生效,这步还会受到SPSR_EL1中保存的部分状态影响;
然后控制流交给 OS,此时 OS 会在执行异常处理函数真正内容前进行软件上下文保存(主要意图是防止内核程序破坏了用户态的程序状态):
将通用寄存器(
x0-x30)压内核栈:因为等会内核可能就要用了;这步是最安全、标准的做法,很多 ISA 也都会这么做,但这显然有性能影响。
因此 ARM 允许优化,即根据 AAPCS (ARM Procedure Call Standard),callee-saved registers (
x19-x29和SP) 如果异常处理函数不会修改它们,并且它调用的函数也遵守 AAPCS,理论上可以不用保存;将
SP_EL0压栈:因为可能后面会调度到不同进程/线程;某些情况,如特定的快速中断 FIQ(而非 IRQ),或者简单的、非 I/O 的系统调用,如果不会主动调度出去,理论上可以不保存;
将
SPSR_EL1/ELR_EL1压栈:必须保存。除了与第二点相同的原因以外,还多了另外一个重要原因:可能会发生嵌套异常(例如处理缺页时又被中断),若不保存很可能会导致之前用户态状态丢失;但
ESR_EL1无关紧要,用完就可以扔了;
而特权级切换回来的时候一般是 OS 主动,所以先软件恢复上下文:弹栈出通用寄存器、SP_EL0、SPSR_EL1/ELR_EL1;
然后 OS 调用 eret 交给硬件恢复:
- 恢复特殊寄存器:
ELR_EL1 -> PC、SPSR_EL1 -> PSTATE(SP_EL0已经软件恢复了); - 当前使用的所有
EL1寄存器全部切换到使用EL0寄存器;
我们发现和进入特权级相比少了些步骤,一个是备份特殊寄存器(内核态有的是计算出来的、有的是保留原先的值、还有的是按需设置的,所以内核态的这些特殊寄存器不需要备份),另一个是 ESR_EL1 只是给内核用的,用户态不需要;
如果涉及调度?
现在考虑更复杂的情况,上面特权态恢复到用户态是没有发生调度的情况。如果决定调度到其他线程,步骤会有不同吗?
答案是会的。假设当前是进程 A 下陷到内核态了,我们上面软件保存状态压入的是 A 的内核栈。现在假设我们需要调度并恢复进程 B 的状态(而不是 A 的),那么我们需要多做一步:内核找到进程 B 的内核栈,将当前 SP_EL1 更改为 B 对应的内核栈顶部地址,然后执行上面的软件恢复动作。
这就够了吗?还不够。你虽然压栈了,但切换到另一个进程时,内核怎么找到 A/B 的内核栈呢?因此还需要把进程上下文信息保存到 PCB 中,将内核栈与进程关联起来。这样要调度到哪个进程,就能顺手从 PCB 中拿出内核栈地址,然后恢复状态了。
现在你可能又又又又有些疑惑了,每个进程都有内核栈?那么内核栈在物理内存的哪里呢?答案需要等到了解内存管理才能揭晓,读者不妨阅读完后文以后再来回顾。
另外,上述过程仍不完整,因为在切换用户态进程时还需要切换用户态页表(内核态页表不用换)、TLB 刷新等操作,不过它们属于内存管理的范畴,也放在内存管理介绍。
知识补充:应用程序需要保存的运行状态称为处理器上下文处理器上下文(Processor Context):
应用程序在完成切换后恢复执行所需的最小处理器状态集合。
处理器上下文中的寄存器具体包括:
- 通用寄存器
x0-x30;- 特殊寄存器,主要包括 PC、SP 和 PSTATE;
- 系统寄存器,包括页表基地址寄存器等;
B. 物理内存管理
应用程序(用户态)和 OS 内核本身最终都需要使用物理内存。用户态程序依靠 OS 为它包装的虚拟内存机制来完成事实上的隔离和足够的资源以供访问。那 OS 依靠谁来分配物理内存?
首先我们知道,内核本身也需要分配内存来运行自身的代码,并且内核也不能在 MMU 开启后再绕过 MMU 翻译,因此它也只能使用虚拟内存地址!
内核在启动时如何拿到虚拟内存?答案是 DIRECT MAPPING 机制。这个机制的内容如下:
在内核启动时,从低地址跳转到高地址执行前(此时还没有抛弃 bootloader 映射的低地址空间),内核会将物理地址的全部空间一口气映射到虚拟地址的高地址空间(
TTBR1),使用大页完成映射(如果 page size 是 4K,则采用 1G 大页,主要看具体实现)。此时只能叫映射,不能叫分配。
是的,只有物理页在内核中的数据结构
struct physical_page中的字段allocated被设置为 1 后才能视作被分配。此时内核中被分配的空间大小只有 bootloader 载入内核镜像的大小(例如 512M)。
映射完成后,内核部分的所有空间的虚拟地址和所有物理地址,只是相差一个 offset(但是由于现代处理器不支持用段管理物理内存,因此只能用页表);
DIRECT MAPPING 本身分配规整,适合使用大页的方法,这也是内核适合使用大页的原因之一。
小贴士:历史上曾经存在 “物理地址大小大于虚拟地址”的情况。这个时候内核怎么 DIRECT MAPPING 来管理物理内存呢?
答案是先 DIRECT MAPPING 映射 892 MB 大小的空间,再在映射的内核空间上方加一个滑动窗口,通过不断更改内核页表的方式来写这些物理内存;
如果内核自己需要为自己的数据结构分配空间(一般是立即使用)怎么办?答案是 Buddy System (alloc_page) + SLUB 机制 (kmalloc);
这两个机制不是一开始就想出来的,这是工程学的沉淀。
- Buddy System 高效地、高利用率地以页为粒度向内核提供各种 page size 倍大小的空间。这个算法和物理页数据结构由内核定义的数据结构
struct physical_page管理,不在 VMA 中,只记录在 buddy system 空闲链表中。分配的页一般不允许 evict / swap out; - SLUB 机制则按照内核调用
kmalloc指定的需求,从资源池 / Buddy System (如果资源池不够) 那里获得的合适大小的资源并返回,极大降低内部碎片和资源浪费。如果有一类数据结构或分配模式大量地出现(例如dentry),则专门为这个大小准备一个资源池,以增强性能; - 如果内核一次性需要 4K (一个页大小) 或更多的数据,内核应该自己懂事地调用
alloc_page来申请,而不是kmalloc; - 无论是 Buddy System 还是 SLUB,分配的内存地址都是 DIRECT MAPPING 的(即它们分配的物理地址直接对应到相差 offset 的内核空间,和最开始的映射是一样的);
如果内核自己需要分配一块超大的空间,并且希望享受用户态 on-demand paging 的性能,怎么办?答案是特殊的 vmalloc 方法。
它和用户态的分配思路一样,on-demand paging,并且这样分配的空间允许 swap out(这个 OS 可以自定义);需要时直接从 buddy system 按页取资源;
注意:使用
kmalloc创建的空间不会被 swap,确保内核关键数据结构不会在运行时不可用。
vmalloc 分配的虚拟内存区域一般情况会在 DIRECT MAPPING 区域更高的地址(如下图 KBASE + 0xFFFF_FFFF ~ 0xFFFF_FFFF_FFFF_FFFF 区域),由内核页表管理到物理内存的映射(可以 swap out)。
如果用户态应用程序通过 malloc 向内核申请应用程序空间,怎么办?就是 ICS 的内容了!
- 若这块空间不大,则通过
brk分配堆。那应用程序的堆空间从哪来?答案是应用程序启动时 OS 会在载入可执行程序的同时预映射一些页给到应用。- 如果预映射的页用完了,内核需要通过页粒度的物理内存管理找到一个空闲的物理页(就是上面说的,直接通过 buddy system 拨一个物理页)并映射好给应用程序;
- 若这块空间很大,通过
mmap直接映射。内部实现是,只是先在 VMA 记录一下,然后 on-demand paging(拨物理页的方法同上);
这样我们会发现,其实任何应用程序已经被分配物理地址的 VM,都有在内核空间对应的区域(映射到同一段物理内存)。
总结一下,任意一个进程虚拟内存区域应该是这样的:
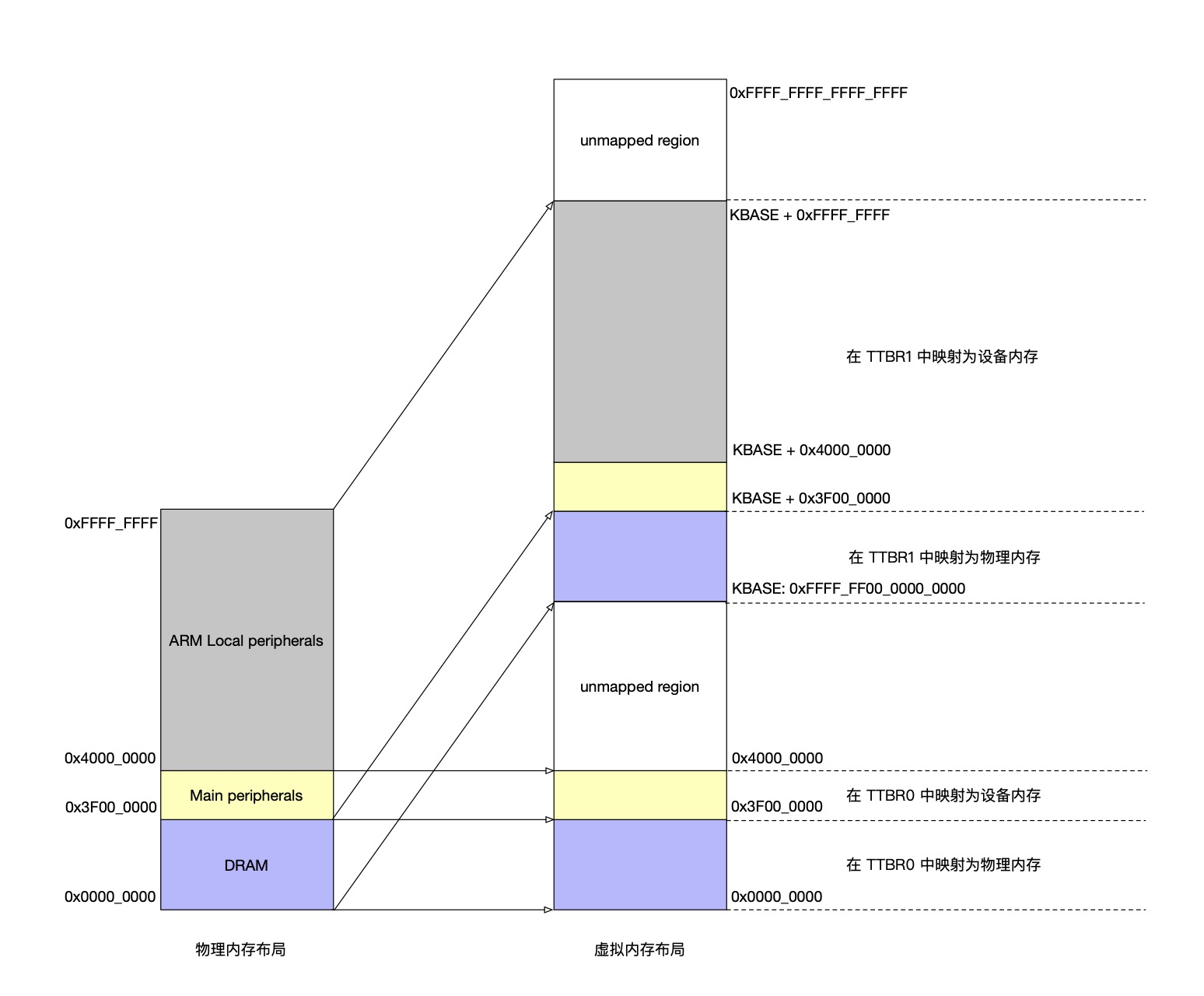
从低地址到高地址分别为:用户态程序空间、设备空间(不在 user space 中)、unmapped region、direct mapping area(全量物理内存映射)、vmalloc 或 ioremap 动态占用空间、kernel 数据结构(如 kernel stack、kernel task struct 等等)、kernel code/data 区;
然后由于 kernel 始终有 direct mapping 的区域,就意味着它能看到物理内存上的所有数据结构。
C. 虚拟内存管理
OS 给用户态程序提供的虚拟内存又是如何实现的?
在 OS 演变历史上,人们主要尝试过 3 种管理用户态程序内存方案:
直接使用物理地址。问题是:干扰性、扩展性、安全性。因此我们需要增加一层隔离,让应用无法直接看见物理地址;
虚拟内存 + 翻译机制(地址分段)。有应用整段分配的,也有更细粒度的:

随着物理内存与虚拟内存的差距增大、应用对于资源需求日益增长,人们很快发现,这种方法对物理内存连续性的要求:物理内存也必须以段为单位进行分配,导致内存利用率不大(外部碎片,段与段间留下的碎片空间;内部碎片,段内部预留的未使用的碎片空间);
因此分段机制通常存在于 x86 设备,现代操作系统不依赖于分段。
虚拟地址 + 翻译机制(分页)。依赖于页表,并且通过多级页表有效压缩页表大小。略。
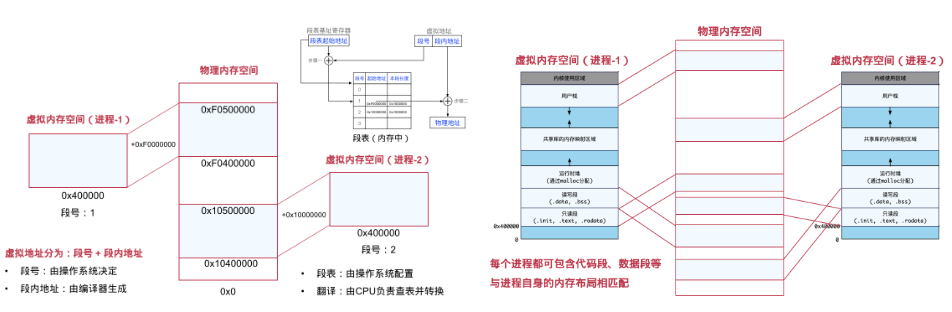
前面说虚拟内存的翻译机制用的是分页,但 OS 对一个用户态程序的虚拟内存内部的管理则采用段来管理。主要考虑:
- 段的数量远少于页,如果使用页管理则应用很可能用不完;
- 通常每一段都有相同的属性,比如只读、可执行等等,可简化管理;
向 VMA 中添加记录的主要途径:
- OS 在创建应用程序时分配(数据段
.rodata、代码段.text等等,也包括栈区域和部分的堆); - 应用程序主动向 OS 发出请求,例如
brk() / mmap()(不论是 file-backed 还是匿名页); - 用户态
malloc;分配小空间或一般空间,则底层一般使用brk(),分配大空间,则底层一般使用mmap();
考虑新的问题:VMA 是否冗余?页表本身是不是已经能够说明了 OS 给当前进程分配的虚拟内存的情况了吗?理论上是这样,页表存放了 VMA 所有保存的数据。但是有以下考量:
- 提升性能。它本身的数据结构就足够高效(红黑树+链表,最新版的 Linux 已经开始用 maple tree 数据结构了)。如何检查应用访问的内存有效?如何实现 kernel page fault handler?总不能把应用的页表扫一遍吧?
- 极大简化
mmap() / munmap() / mprotect()等函数的实现。尤其分配大空间时 on-demand paging 就必须需要 VMA(归根到底还是性能); - 保存额外的信息(例如是否 file-backed、shared/private mapping),便于 OS 实现其他功能;
再次总结虚拟内存的优势:
- 高效使用物理内存:使用 DRAM 作为虚拟地址空间的缓存,将离散的、有限的空间给应用抽象成连续的、充足的空间;
- 简化内存管理:每个进程看到的是统一的线性地址空间;多个进程间方便安全地分享;
- 更强的隔离与更细粒度的权限控制:
- (隔离性)一个进程不能访问属于其他进程的内存;
- (安全性)用户程序不能够访问特权更高的内核信息;
- 不同内存页的读、写、执行权限可以不同;
什么时候不需要:
- 内存地址足够大(用页表开销会逐渐增大,使用段机制访问的优势就会凸显)、性能要求足够高;
D. 全局视角:内核栈是什么?在哪里?
首先搞清楚内核栈官方定义是啥?根据 官方文档:
x86_64 page size (PAGE_SIZE) is 4K.
Like all other architectures, x86_64 has a kernel stack for every active thread. These thread stacks are THREAD_SIZE (2*PAGE_SIZE) big. These stacks contain useful data as long as a thread is alive or a zombie. While the thread is in user space the kernel stack is empty except for the thread_info structure at the bottom.
In addition to the per thread stacks, there are specialized stacks associated with each CPU. These stacks are only used while the kernel is in control on that CPU; when a CPU returns to user space the specialized stacks contain no useful data.
注意到,官方文档说,OS 内核对每个活动线程都有一块内存空间,称为 “thread stack”(线程栈),这就是内核栈的一部分,它的作用就是在对应线程进入内核态时内核需要用的栈。一个 x86_64 的 thread stack 大约 8KB(2 个页大小),当线程在用户态时,内核栈是空的(除了 thread_info 结构体),直到进入内核态才有用。
并且除了 thread stacks,实际上还有与每个 CPU 相关的专门堆栈(Interrupt stack,中断栈),这也能看作内核栈的一部分。这些堆栈只在内核控制 CPU 时使用(用于处理硬中断和 softirq);作用是为内核中断处理提供了更多空间,而无需增加每个线程栈的大小。当 CPU 返回用户空间时,这个专用堆栈也就不包含有用数据了。
嗯?看起来有两种栈都能称为 “内核栈”?
没错,“内核栈” 本身的定义就极为宽泛:操作系统内核为执行流(无论是内核线程还是代表用户进程执行内核代码)在内核态运行时分配的专用内存区域。
而内核栈就是内核线程使用的栈。
这里的 “内核线程” 也是很宽泛的定义,实际上有好几类,常见的例子有:
- 中断下半部处理:
ksoftirqd线程处理延后的软中断任务;- 内存管理: 如
kswapd线程负责页面回收;- 文件系统: 如日志提交 (
jbd2)、数据同步 (flush线程);- 工作队列机制:
kworker线程执行由内核其他部分提交的延迟工作项;- 实现用户线程模型: 在 1:1 线程模型(如 Linux 的 NPTL)中,每个用户线程 LWP 都直接绑定一个内核线程(LWP 即轻量级进程,也就是建立在内核之上并由内核支持的用户线程);
我们上面的 “thread stack” 其实就是 “实现用户线程模型” 的这类内核线程的栈,它一般跟随着用户线程/进程的创建来分配,因此与用户态线程强绑定;
而其他类型的内核线程一般和用户线程一样,都是参与调度的,和用户线程的关系不紧密(是内核通过
kthread_create / kthread_run启动的线程),只不过它们一般受内核专用调度器来调度。
最后补充一下全局视角:以 Linux 为例,内核栈在哪里?更准确地说,“实现用户线程模型” 用到的内核栈(thread stack)在哪里?
这个问题比较复杂,我们先从几个简单的事实出发:
在任何时刻,一个 CPU 核心正在使用的内核栈只有一个。这是当 CPU 在 kernel mode 执行代码时(例如处理系统调用、中断、异常、调度代码)所使用的栈。这个栈的指针(例如 x86 的
RSP寄存器或 AArch64SP_EL1)指向当前正在使用的内核栈顶部;但是,一个 CPU 核心会处理多个进程/线程。每个用户空间的进程/线程在陷入内核态时,都需要使用自己独立的内核栈(有且仅有对应的一个)。
现在回顾之前的知识 “特权级切换时 CPU 和 OS 应该做什么”,我们知道如果涉及进程切换,那么在内核态需要先切换内核栈,再回用户态。
另外,只是压栈还不行(否则想要切换到目标进程却发现找不到对应内核栈的位置。。),还需要把进程上下文信息保存到 PCB 中。
然后内存管理层面还需要切换用户态页表(更新
TTBR0_EL1)、刷新 TLB 等等。注 1:从哪里更新
TTBR0_EL1?每个进程的页表基地址则放在进程struct task_struct->struct mm_struct->pgd_t *pgd字段中。注 2:
struct mm_struct除了页表基地址,还会存放 VMA list、堆栈信息、其他内存映射信息、页表锁等;
好了,知道了我们在这些地方要用到内核栈,我们只要捋清除内核栈从创建到销毁的一系列流程,就知道它究竟在哪了。
我们知道,DIRECT MAPPING 是内核虚拟地址空间中一个巨大、连续的区域,提供虚拟地址到物理地址的简单线性关系的转换,它的目的就是提供一种高效访问几乎任何物理内存页的方式,避免为每次访问建立复杂页表映射的开销。内核需要操作内存数据结构(如上面提到的 struct page、SLAB 分配器对象)、Buddy System 机制、或 DMA 缓冲区时,常使用此区域;
但内核栈是动态的、是为每个进程/线程动态分配的(通常在进程创建时 fork()/clone()),它与特定的执行上下文(进程/线程)紧密绑定。
就这点上来说,内核栈就像内核使用的比较大的数据结构,分配的方法就上面两种:一个是直接用 alloc_page 这样的方法从 buddy system 那里拿物理页(DIRECT MAPPING),另一个是使用 vmalloc 分配一个大的空间,然后 on-demand paging。
不考虑
kmalloc的原因参见前文,栈的大小也不小了。
事实上,一开始 Linux 设计者选择了使用 buddy system 而非 vmalloc 来分配内核栈,是因为性能考量:vmalloc 通常 on-demand paging 分配的连续虚拟内存,但物理内存不一定连续,这对一般情形是有用的,但内核栈使用频繁,如果每次都走虚拟地址页表的翻译,性能会很差;因此内核栈需要尽量保证物理空间上连续,能受益到 locality 的性能。
但在 Linux 4.14 以后,引入了 VMAP_STACK(参见链接)机制,允许采用 vmalloc 申请的内存作为内核栈,只需要使能 CONFIG_VMAP_STACK 内核选项即可。这样可以利用 vmalloc 自身的内存边界检查的特性,提供类似 guard page 这样的栈溢出检测的能力。
最后在进程退出时,内核会释放其内核栈占用的物理页帧,并解除对应的虚拟地址映射(清理内核页表)。
所以问题解决了,内核栈要么在 DIRECT MAPPING 区域(如果直接从 buddy system 拿物理页),要么在 vmalloc 分配的某段连续虚拟内存中(如果启用 VMAP_STACK),当然如果是由 vmalloc 分配,那么分配时 OS 会额外标记内核栈不允许 swap-out(通过标记物理页数据结构 struct page 的特殊字段 GFP 来禁止换出)。
- wechat
- alipay











